4:26 pm
-
- -1
- +5
Line HistoryCommit Activity52 week commits volumeCommits by dayCommits by hourMost active committers (90 days)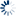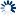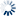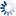
|
 |
Monday 02 Jan 2023
4:26 pm
Thursday 29 Dec 2022
3:17 pm
3:14 pm
2:02 pm
1:54 pm
1:52 pm
1:05 pm
Wednesday 28 Dec 2022
10:25 am
Saturday 24 Dec 2022
5:33 pm
5:21 pm
Thursday 22 Dec 2022
5:12 am
3:51 am
3:39 am
3:36 am
Tuesday 20 Dec 2022
4:20 pm
Thursday 15 Dec 2022
8:30 pm
8:28 pm
2:47 pm
2:41 pm
2:36 pm
2:27 pm
2:26 pm
2:17 pm
2:06 pm
1:18 pm
1:17 pm
1:06 pm
12:40 pm
12:39 pm
|