The content repository does not place any restrictions on the methods employed for delivering content via a public server infrastructure. Applications are free to query the repository and process the data in any way desired.
Although there are no restrictions on publishing methodology, the repository API is intended to facilitate generic template-based publication, regardless of the specific presentation layer used. The following diagram illustrates the steps typically involved in such a publication process:
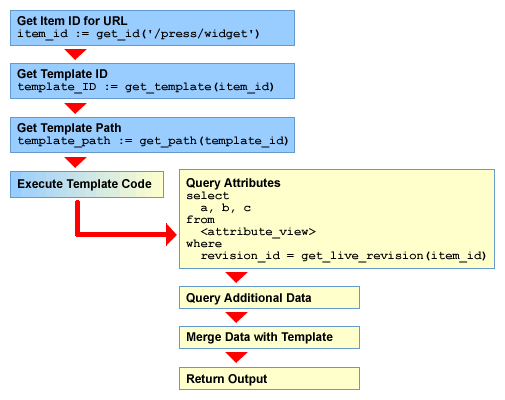
In general, there is an initial resolution step in which the server must identify the appropriate content item and then decide which template to actually parse. Following that is an execution step, during which setup tasks associated with the template are performed. Finally, the merging step combines the data and layout into a rendered page.
The primary mechanism for matching URLs to Content Items are virtual URL handlers, .vuh files. An explanation of virtual URL handlers can be found in the tutorial on the Request Processor.
Here is an example index.vuh file that you can adapt to your own purposes:
# Get the paths
set the_url [ad_conn path_info]
set the_root [ns_info pageroot]
# Get the IDs
set content_root \
[db_string content_root "select content_item.get_root_folder from dual"]
set template_root \
[db_string template_root "select content_template.get_root_folder from dual"]
# Serve the page
if { [content::init the_url the_root $content_root $template_root] } {
set file "$the_root/$the_url"
rp_serve_abstract_file $file
} else {
ns_returnnotfound
}
The content_root and template_root parameters select the content and template root folders. In the example, they are just the default roots that the content repository initializes on installation. If you want to store your content completely independent from that of other packages, you can initialize your own content root and pass that folder's ID on to content::init.
To publish content through URLs that are underneath /mycontent you need to do the following:
If you use the example index.vuh file above unaltered for requests to my_content, a request for http://yourserver/mycontent/news/articles/42 would request the content item /news/articles/42 from the content repository on the default content root folder.
When you create a new content type or add an attribute to an existing content type, a view is created (or recreated) that joins the attribute tables for the entire chain of inheritance for that content type. The view always has the same name as the attribute table for the content table, with an "x" appended to distinguish it from the table itself (for example, if the attribute table for Press Releases is press_releases, then the view will be named press_releasesx. Querying this view is a convenient means of accessing any attribute associated with a content item.
As a shortcut, the item's template may call content::get_content in its Tcl file in order to automatically retrieve the current item's attributes. The attributes will be placed in a onerow datasource called content . The template may then call template::util::array_to_vars content in order to convert the onerow datasource to local variables.
In addition to the "x" view, the Content Repository creates an "i" view, which simplifies the creation of new revisions. The "i" view has the same name as the content table, with "i" appended at the end. You may insert into the view as if it was a normal table; the insert trigger on the view takes care of inserting the actual values into the content tables.
Templates often display more than simple content attributes. Additional queries may be necessary to obtain data about related objects not described directly in attribute tables. The setup code associated with a template typically performs these queries after the initial query for any needed attributes.